Analyse statique du code et Linting
Dans cette unité de cours, vous apprendrez l'intérêt d'utiliser des analyseurs de code statiques, les composants techniques sur lesquels ils s'appuient en interne, et comment vous pouvez utiliser efficacement l'analyse statique du code dans votre projet pour améliorer la qualité du code.
Résumé de la lecture
L'analyse statique du code fournit des normes de qualité du code supplémentaires qui ne peuvent pas être obtenues avec des tests classiques.
À propos de l'analyse du code
L'analyse de code est le processus d'examen du code source pour identifier les problèmes et améliorer la qualité du logiciel. Vous avez déjà vu deux techniques d'analyse de code : Débogage et Tests unitaires.
- La débogage est un moyen d'analyser le code étape par étape, en examinant les valeurs des variables tout au long de l'exécution.
- Les tests unitaires performent la vérification automatisée du comportement d'une fonction spécifique, en vérifiant les sorties pour des entrées données.
Les deux nécessitent l'exécution du code. Ce sont des techniques d'analyse de code dynamiques.
Y a-t-il un inconvénient à l'analyse dynamique du code ?
L'exécution du code peut ralentir considérablement l'analyse du code, surtout si l'analyse nécessite une interaction humaine, comme c'est le cas avec le débogage.
Limitations générales
Peu importe la technique, l'analyse logicielle n'est pas triviale, et des erreurs pendant le diagnostic peuvent se produire :
Pour un bogue ou un rapport donné, nous pouvons distinguer quatre catégories de diagnostic :
- Vrai positif : Un certain bogue a été signalé, et c'est effectivement un bogue.
- Faux positif : Un certain bogue a été signalé, mais ce n'est en réalité pas un bogue.
- Faux négatif : Un certain bogue existe, mais n'a pas été signalé.
- Vrai négatif : Un certain bogue n'existe pas, et il n'a pas été signalé non plus.
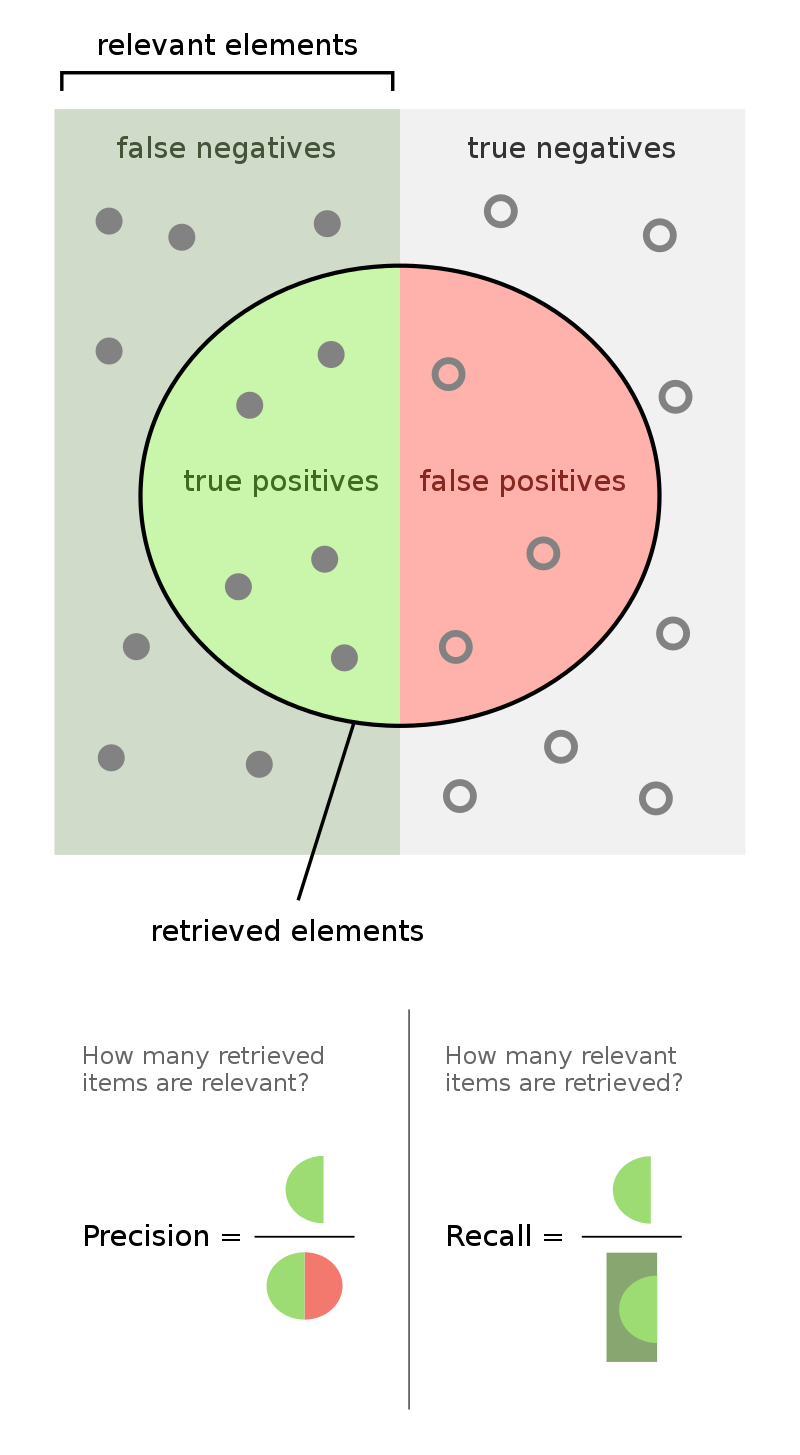
Source: Wikipedia - Precision and Recall
Limitations de l'analyse de code dynamique
- L'exécution du programme (analyse dynamique) ne peut donner un aperçu que des caractéristiques comportementales.
- Cependant, il existe d'autres métriques de qualité :
- Formatage du code
- Documentation
- Simplicité du code
Tests
Les tests sont indispensables pour le développement de logiciels de qualité. Cependant...
Les tests peuvent-ils prouver l'exactitude d'un programme ?
Malheureusement, non. Les tests ne peuvent trouver que des bogues, mais ne peuvent prouver leur absence. Des programmes peuvent être très bien testés et avoir encore des bogues.
Débogage
Le débogage fournit un aperçu énorme de l'état arbitraire du programme. Mais, en tant qu'approche manuelle, il est très chronophage et doit idéalement être répété chaque fois que le code évolue.
Analyse statique du code
- L'analyse statique du code consiste à analyser le code sans exécuter le programme.
- C'est-à-dire que nous inspectons le code directement, sans tester son comportement.
- En principe, la forme la plus primitive de l'analyse statique du code est : "Lire le code source et réfléchir aux bogues possibles."
Malheureusement...
"Toutes les propriétés sémantiques non triviales des programmes sont indécidables. --Rice 1951"
Qu'est-ce que cela signifie en pratique ?
Il n'est pas possible d'avoir une analyse de programme saine et complète. Vous aurez toujours des faux positifs ou des faux négatifs. Le mieux que vous puissiez atteindre est une approximation.
- Complet : Au moins, nous avons trouvé tous les bogues (et signalé quelques faux positifs).
- Sain : Les bogues trouvés sont tous de véritables bogues (mais nous pourrions avoir quelques faux négatifs).
Bases de l'analyse statique du code
- Ce qui est commun à toutes les formes d'analyse statique du code est l'analyse syntaxique du code, pour raisonner sur sa structure sans exécution.
- L'analyse syntaxique est également la première étape de chaque compilation : essayer de comprendre la structure du code, en décomposant le code source en "blocs atomiques".
L'analyse syntaxique se compose en réalité de deux composants :
Analyseur lexical
Lexer (également appelé scanner ou tokenizer) : itère sur le code et identifie le token approprié pour chaque élément. Par exemple, en utilisant JLex.
L'analyseur lexical prend en entrée du code source pur :

- En fonction du langage de programmation utilisé, différents tokens sont définis.
- Pour Java, il n'y a que 6 types de tokens :
| Token | Exemple |
|---|---|
| Mot-clé | abstract, boolean, byte, ... |
| Identifiant | noms de variables, noms de fonctions, ... |
| Littéral | valeurs concrètes, p. ex. 42 |
| Opérateur | <, >, =, +, ... |
| Séparateur | ;, [, ], {, }, ... |
| Commentaire | //, /* ... */, /** ... */ |
Regardez aussi ce tableau de référence...
Pouvez-vous identifier les tokens ? (Cliquez pour vérifier votre réponse)

Vous pouvez inspecter l'AST du code Java en utilisant le plugin JDT AstView.
Analyseur
L'Analyseur parcourt le programme tokenisé et construit un arbre de syntaxe abstraite (AST).
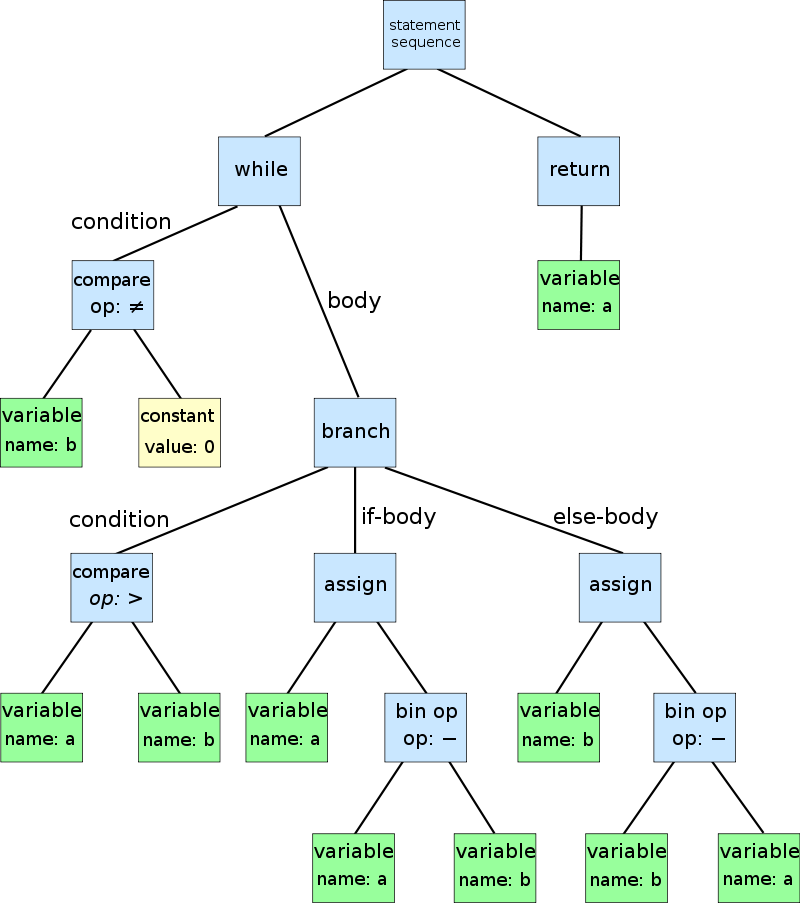
Crédits d'image : https://en.wikipedia.org/wiki/Abstract_syntax_tree
Qu'est-ce qu'un AST ?
- Structure de données en arbre
- Chaque nœud stocke des informations abstraites, par exemple le type de token
- Représente la structure du programme
Pourquoi voudriez-vous un AST ?
- L'AST permet des optimisations, par exemple :
- suppression de code inaccessible (dead code).
- evaluation des expressions constantes pendant la compilation (contant folding).
- L'AST donne beaucoup d'informations sur la validité sémantique. Si l'AST existe, cela signifie que le code respecte la grammaire du langage.
- L'AST peut être utilisé pour le raisonnement, par exemple, pour trouver du code dupliqué (Common Subexpression Elimination)
L'AST est utile, mais pas strictement nécessaire...
L'analyse statique, tout comme la compilation, n'a pas nécessairement besoin d'un AST. Bien que l'AST soit très utile, les langages peuvent être analysés directement après la tokenisation. De même, les compilateurs n'ont pas nécessairement besoin d'un AST. Si aucune optimisation n'est nécessaire, un compilateur peut traduire directement le code à partir des sources tokenisées. Les compilateurs primitifs, qui n'utilisent pas d'AST, sont également appelés des compilateurs à passage unique.
La plupart des techniques d'analyse de code statique (et certainement les plus puissantes) utilisent un AST.
Vue d'ensemble des techniques d'analyse
Les techniques les plus importantes pour l'analyse statique du code sont :
- Linting (grep) : Recherche dans l'AST des motifs spécifiques.
- Exemple : ast-grep
- Note :
grep(la commande Unix) signifie "Global Regular Expression Print".ast-grep, tout comme la commande Unix, utilise des expressions régulières pour rechercher (et trouver) des structures. La différence est quegrepde Unix fonctionne sur des fichiers texte, tandis queast-grepopère directement sur l'AST.
- Exécution symbolique : Déterminer quels inputs provoquent l'exécution de chaque partie du programme. Exécuter le programme sans "valeurs réelles", essayer de trouver des inputs pathologiques.
- Analyse de flux de données : Analyser où dans le programme les variables sont définies et utilisées. Peut également être utilisé pour l'optimisation de l'AST.
- Vérification de modèle : Vérifier le modèle AST et tenter d'exclure les risques de sécurité, par exemple, un crash.
- Vérification formelle : Utiliser des méthodes formelles de mathématiques pour prouver l'exactitude du logiciel.
Statique != Automatisé
Bien que toutes les techniques ci-dessus soient des techniques d'analyse statique, il existe également une gamme de vérification allant de manuelle à automatisée. Ce n'est pas parce que l'analyse utilise un code statique qu'elle est entièrement automatisée !
Dans le contexte des techniques dynamiques
En tenant compte du statique par rapport au dynamique, et du manuel par rapport à l'automatique, nous pouvons catégoriser les techniques d'analyse :

Les experts en sécurité utilisent des techniques hybrides
Les hybrides sont possibles. Des recherches récentes, par exemple, combinent l'Exécution Symbolique intense en calcul avec des techniques de Fuzzing. Le programme est d'abord analysé avec des techniques d'analyse de code statique, une fois un ensemble d'inputs probablement pathologiques trouvé, nous passons au Fuzzing et bombardons le programme à l'exécution avec des mutations d'input pour voir ce qui se passe. Cette technique a révélé de graves bogues de sécurité qui étaient passés inaperçus dans des logiciels publics pendant des années. Voir Driller
Pour le reste du cours, nous ne sommes pas trop intéressés par le fonctionnement interne des outils d'analyse. Si vous êtes intéressé par les détails, il existe un excellent cours sur la Sécurité des Programmes : INF889 (avec Quentin)
Outils d'analyse de code
Nous ne voulons pas seulement des techniques qui, en théorie, aident à améliorer la qualité du code. Nous voulons des outils qui assurent fiablement que notre code s'améliore. Ils doivent être exécutables et automatisés.
- Exécutable : Les vérifications de qualité de l'outil sont facilement accessibles, idéalement depuis l'IDE.
- Automatisé : Les vérifications de qualité de l'outil sont systématiquement invoquées et rejettent le mauvais code,
idéalement dans le cadre du processus de construction.
- Rejeté de l'exécution : L'outil ne permet pas d'exécuter du code de faible qualité.
- Rejeté de la diffusion : L'outil ne permet pas de partager du code de faible qualité via git.
Dans le reste de cette leçon, nous allons couvrir quelques outils d'analyse de code essentiels et comment ils sont utilisés.
Mise en surbrillance de la syntaxe dans l'IDE
Les IDE fournissent une mise en surbrillance de la syntaxe. Les éditeurs de texte de base ne le font généralement pas.
- Dans le premier laboratoire, vous avez programmé dans un éditeur de texte de base, sans mise en surbrillance de la
syntaxe.
- Le seul moyen de trouver des erreurs de syntaxe était de compiler, en utilisant
javac. - Vous l'avez probablement trouvé lent, fastidieux et incommode.
- Le seul moyen de trouver des erreurs de syntaxe était de compiler, en utilisant
La mise en surbrillance de la syntaxe est une vérification pré-compilation du code source, pour vérifier qu'il correspond à la grammaire du langage.
- À chaque changement de code : l'IDE exécute un tokenizeur et un analyseur.
- Les éléments de code tokenisés sont mis en surbrillance en couleur.
- Les constructions qui ne peuvent pas être analysées en un AST valide sont mises en surbrillance comme des erreurs de
syntaxe.
- Texte en rouge
- Barre rouge sur la marge droite
- Point d'exclamation en haut à droite

Voir aussi : documentation du lexer et de l'analyseur d'IntelliJ Jetbrains.
Checkstyle
Pour le but d'une analyse syntaxique, les linters ne construisent généralement pas d'AST et raisonnent directement sur la structure de tokens extraite. Les linters se concentrent généralement sur l'application de conventions de codage visuelles :
- Indentation
- Placement des parenthèses
- Retours à la ligne
- Nommage des variables
- ...
Un exemple est Checkstyle, que nous avons déjà vu en classe. Checkstyle utilise un fichier de configuration pour s'assurer que tous les membres de l'équipe utilisent les mêmes conventions de code visuelles. Pourquoi est-ce utile ?
- Le code est plus facile à lire si tout le monde utilise la même convention.
- (Beaucoup) moins de conflits lors du travail avec un VCS, par exemple git.
Plugin IDE Checkstyle
- Checkstyle est disponible en tant que plugin IDE.
- Pour ce cours, nous utilisons le google checkstyle coding convention comme fichier de configuration.
Description complète de l'installation dans l'unité de cours sur IDEs.
Plugin Maven Checkstyle
- Checkstyle peut être appliqué dans le cadre du processus de construction.
- Lorsque le triangle vert est configuré pour invoquer Maven (
mvn clean package), cela garantit que votre code ne sera pas compilé / lancé à moins qu'il n'y ait aucune violation de Checkstyle. - Le seul changement nécessaire est d'activer le plugin dans le fichier
pom.xmlde votre projet :
<!-- Plugin to refuse build in case of checkstyle violations-->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-checkstyle-plugin</artifactId>
<version>3.6.0</version>
<configuration>
<configLocation>google_checks.xml</configLocation>
<consoleOutput>true</consoleOutput>
<violationSeverity>warning</violationSeverity>
<failOnViolation>true</failOnViolation>
<failsOnError>true</failsOnError>
<linkXRef>false</linkXRef>
</configuration>
<executions>
<execution>
<id>validate</id>
<phase>validate</phase>
<goals>
<goal>check</goal>
</goals>
</execution>
</executions>
</plugin>
ça a l'air pénible, quel est l'intérêt d'une telle configuration ?
Bien que des règles strictes de checkstyle puissent ralentir l’écriture du code, elles empêchent l'exécution et la propagation de mauvais code. À long terme, l'absence de conflits de fusion et la productivité constante des développeurs sont plus importantes que la capacité de hacker du code rapidement. Un linter strict est fastidieux sur le moment, mais il porte ses fruits à long terme.
Complexité
Il existe souvent plusieurs façons de coder la même fonctionnalité.
- Dans le meilleur des cas, le comportement d'une solution complexe est le même que celui d'une solution plus simple.
- Mais le code complexe est difficile à comprendre, à utiliser et à maintenir.
- Votre code ne doit pas seulement être correct, mais aussi aussi simple que possible.
Complexité cyclomatique
La complexité cyclomatique vous donne une idée de la complexité de votre code et vous fournit des indications sur la façon de le simplifier.
De manière plus concrète, pour déterminer une métrique de complexité cyclomatique, nous utilisons l'AST pour créer une représentation du graphe de flot de contrôle du programme :
- Les structures de contrôle dans l'AST se traduisent par des nœuds de graphe : début et retour de fonction,
if,else, boucles, blocs de code. - Les chemins d'exécution entre les structures de contrôle se traduisent par des arêtes de graphe.
En fonction des propriétés du graphe de flux de contrôle, nous calculons une métrique de complexité, par méthode :

Il n'existe pas de plugin Maven dédié, mais il existe un plugin IDE pour un retour visuel instantané sur la complexité, et Checkstyle (pour lequel il existe un plugin Maven) peut être configuré pour évaluer la complexité cyclomatique. ( Non couvert dans ce cours.)
Spotbugs
Spotbugs (anciennement FindBugs) est un analyseur AST très performant, qui recherche systématiquement dans votre code les bogues potentiels, ou même des constructions de code qui mènent souvent à des bogues.
- Exemple : si vous avez un getter retournant un objet mutable, FindBugs vous en informera.
Plugin IDE Spotbugs
Spotbugs est disponible en tant que plugin IDE. Après installation, vous pouvez accéder à un nouveau menu SpotBugs sur la barre de base, pour analyser votre projet ou un fichier spécifique à la recherche de bogues potentiels.

Plugin Maven Spotbugs
Tout comme javadoc et checkstyle, vous pouvez ajouter Spotbugs à votre configuration pom.xml. Spotbugs sera invoqué à
chaque mvn clean package.
<reporting>
<plugins>
<plugin>
<groupId>com.github.spotbugs</groupId>
<artifactId>spotbugs-maven-plugin</artifactId>
<version>4.8.6.5</version>
</plugin>
</plugins>
</reporting>`
Info
Notez que Spotbugs ne vous empêchera pas d'exécuter votre code, même si des extraits risqués sont trouvés. Il génère uniquement un rapport de test.
PMD
Pour les très (très, très) courageux. Découvrez PMD (Project Meets Deadline).
- Il n'est en fait pas facile d'écrire du code pour lequel PMD n'a absolument aucune plainte. (Alerte faux positif !)
- Mais vous pouvez être sûr que votre code s'améliore considérablement à mesure que vous essayez (et vous apprendrez beaucoup).
Plugin IDE PMD
PMD est disponible en tant que plugin IDE. Après installation, vous
pouvez exécuter l'analyse statique du code dans Outils -> PMD -> Exécuter prédéfini -> Tout.
Plugin Maven PMD
Tout comme javadoc, checkstyle et spotbugs, vous pouvez ajouter PMD à votre configuration pom.xml. PMD sera invoqué à
chaque mvn clean package. Pour exécuter uniquement PMD, utilisez : mvn clean pmd:check.
<!-- PMD static code analysis -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-pmd-plugin</artifactId>
<version>3.26.0</version>
<configuration>
<rulesets>
<!-- full list: bestpractices, codestyle, design, documentation, errorprone, multithreading, performance-->
<ruleset>/category/java/bestpractices.xml</ruleset>
</rulesets>
<!-- failOnViolation is actually true by default, but can be disabled -->
<failOnViolation>true</failOnViolation>
<!-- printFailingErrors is pretty useful -->
<printFailingErrors>true</printFailingErrors>
<linkXRef>false</linkXRef>
</configuration>
<executions>
<execution>
<goals>
<goal>check</goal>
</goals>
<!-- Enforce the pmd:check goal is auto-executed during package phase-->
<phase>package</phase>
</execution>
</executions>
</plugin>
La configuration ci-dessus est la plus basique et ne vérifie que le style de code. Pour libérer toute la puissance de
PMD, modifiez la balise ruleset :
<ruleset>/category/java/bestpractices.xml</ruleset>
<ruleset>/category/java/codestyle.xml</ruleset>
<ruleset>/category/java/design.xml</ruleset>
<ruleset>/category/java/documentation.xml</ruleset>
<ruleset>/category/java/errorprone.xml</ruleset>
<ruleset>/category/java/multithreading.xml</ruleset>
<ruleset>/category/java/performance.xml</ruleset>
Littérature
Inspiration et lectures complémentaires pour les esprits curieux :
- Stiévenart Quentin : INF889A
- Article de blog : Qu'est-ce qu'un linter
- Moller & Schwartzbach : Analyse statique des programmes *
Jetbrains : Documentation sur le lexer et le parser.