Tests II
Dans ce cours, nous examinerons des concepts avancés de test, entre autres, pour garantir que nos tests ne sont pas seulement complets, mais aussi pertinents.
Tests de mutation
- Une grande partie de ce cours a porté sur les outils et les pratiques qui peuvent être appliqués pour maintenir la
qualité du code :
- Checkstyle
- Linters
- Documentation
- Tests
- Systèmes de construction
- Intégration continue
- Ce que ces outils ont en commun, c'est qu'ils offrent des garanties sur la maintenabilité de votre code à long terme. Ils assurent collectivement un certain niveau de qualité dans le code de votre application.
- Cependant, il y a une partie de votre codebase que nous avons plutôt ignorée : la qualité de vos tests !
Existe-t-il une métrique fournissant un aperçu de la qualité des tests ?
Couverture de code. Un rapport de couverture, comme celui généré par le plugin jacoco, révèle quelle fraction du code a été testée. Une faible couverture indique des tests insuffisants. Cependant, l'inverse n'est pas nécessairement vrai : une couverture élevée n'est pas une garantie fiable de tests de qualité.
Dans ce qui suit, vous apprendrez une pratique de développement logiciel pour évaluer et améliorer de manière fiable la qualité des tests : Les tests de mutation.
Illustration : Tests zombies
Les mauvais tests sont comme des zombies :
- Ne servent à rien : Ils ne fournissent aucune indication sur d'éventuels problèmes dans le code.
- Consomment des ressources : Ils ralentissent le processus de construction.
- Se multiplient rapidement : Ils sont facilement créés et ont tendance à se multiplier vite, par des développeurs se concentrant sur la couverture et le copier-coller, ainsi que par des vibe-coders qui ne comprennent pas leur propre code.
Exemple d'un test zombie :
@Test
public void isPrimeTest() {
// Calls production code, but does not assert anything.
PrimeChecker.isPrime(10);
}
- Vous voulez avoir le moins de tests zombies possible dans votre codebase.
- Mais comment trouver les tests zombies ?
- Chercher les tests vous-même peut être long et fastidieux.
- Les tests zombies ne sont pas toujours aussi évidents à repérer que dans l'exemple ci-dessus.
- Les supprimer pourrait encore réduire la couverture, ce qui pourrait vous inciter à les conserver.
Combattre les zombies avec des mutants
- Une réflexion simple pour commencer :
- Si vos tests sont bons, ils identifieront les bogues dans votre programme.
- Si vos tests ne sont pas bons, ils échoueront à identifier les bogues dans votre programme.
- Si nous ajoutions artificiellement un bogue au code de production...
- ... et aucun test ne échoue : Il semble qu'il y ait au moins un test zombie. (C'est-à-dire, tous les tests qui couvrent la ligne que nous avons modifiée.)
- ... et au moins un test échoue : Nous ne pouvons pas conclure qu'il y a un test zombie.
Formalisation des tests de mutation
Comment pourrions-nous formaliser le processus illustré ci-dessus ?

- Tester notre codebase de manière classique
- Modifier notre codebase (mutation)
- Relancer les tests
- Évaluer s'il y a des tests zombies
Que testons-nous réellement ici ?
Les tests de mutation ne nous disent rien sur la qualité du code de production, mais sur la qualité des tests ! Les tests de mutation signifient "tester vos tests".
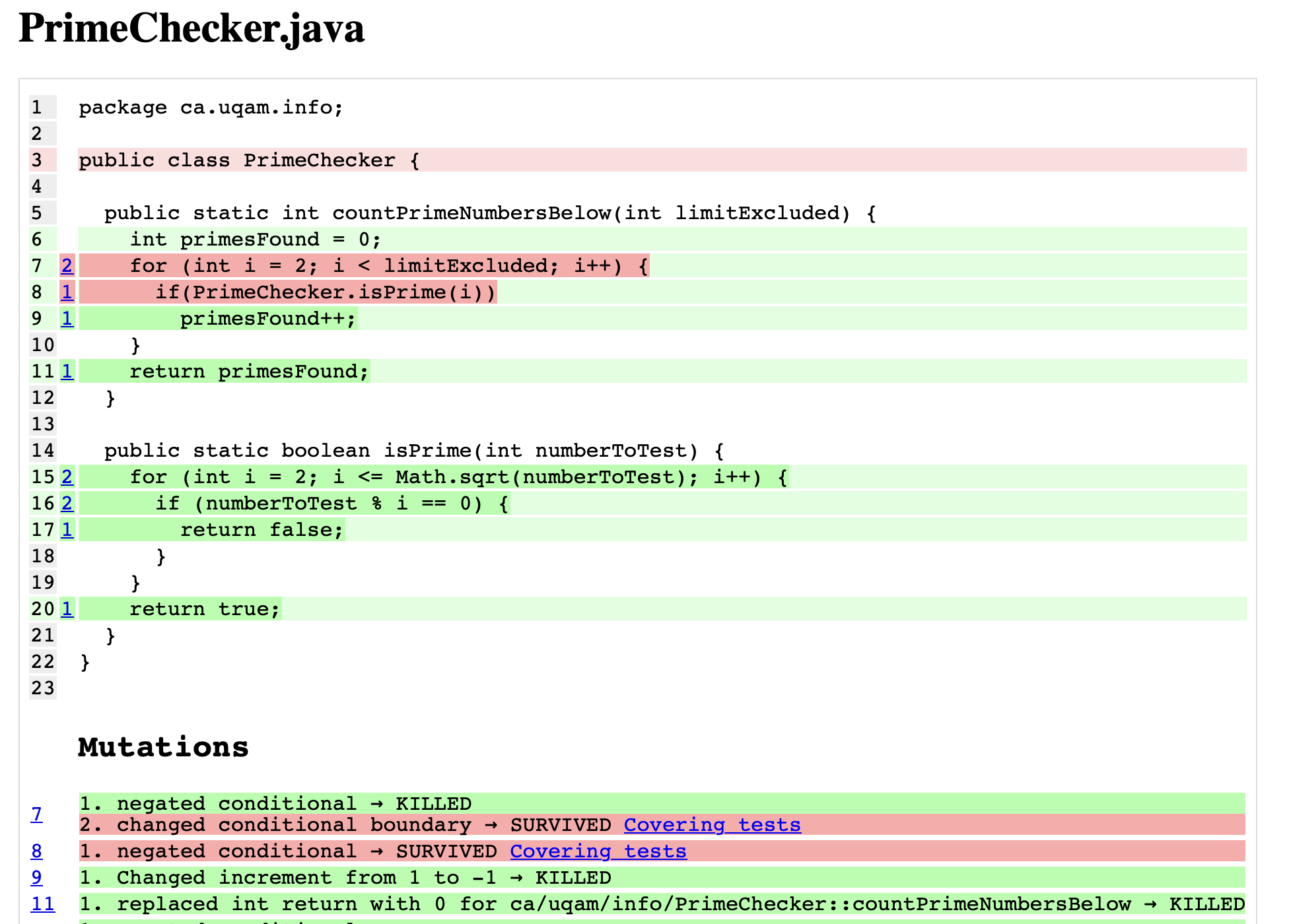
Exemple de mutation
- Considérons le code de production contenant une fonction :
Et avoir le test suivant :
public static int countPrimeNumbersBelow(int limitExcluded) { int primesFound = 0; for (int i = 2; i < 10; i++) { if (PrimeChecker.isPrime(i)) primesFound++; } return primesFound; } public static boolean isPrime(int numberToTest) { for (int i = 2; i <= Math.sqrt(numberToTest); i++) { if (numberToTest % i == 0) { return false; } } return true; }java @Test public void testPrimesBelow10() { Assert.assertEquals(4, PrimeChecker.countPrimeNumbersBelow(10)); } - Nous msodifions notre codebase : Introduction d'une mutation de "conditionnelle négative", c'est-à-dire une variante de notre code original :
- Nous relançons nos tests : Tous les tests passent toujours.
- Nous comparons les résultats des tests et constatons qu'il n'y a aucun changement dans les résultats des tests.
Que pouvons-nous conclure de cela ?
Nous avons un test zombie ! Le test que nous avons est insensible à une grave erreur de programmation. Un test zombie existe, consomme des ressources, affiche une barre de succès verte, contribue à la couverture, mais ne garantit pas de manière fiable la qualité du code.
Créer une armée de mutants
- L'étape logique suivante n'est pas de tester une seule mutation, mais de créer des mutants de manière excessive.
- Pour chaque mutant, nous définissons :
- Si aucun test ne échoue après l'introduction de la mutation du code : Le mutant a survécu, il y a un zombie !
- Si au moins un test échoue après l'introduction de la mutation du code : Le mutant a été tué, aucun zombie trouvé par cette mutation.
- Les mutations du code original sont créées en utilisant un ensemble de règles de mutation :
- "Conditionnelle négative" : introduire un signe
!devant une expression booléenne. - "Appel de méthode void" : Supprimer l'appel à une méthode de type
void. - "Incréments" : Remplacer un
++par un--; - et bien d'autres...
- "Conditionnelle négative" : introduire un signe
Attendez, tout ça n'a aucun sens. Cela va juste casser mon programme !
Exactement ! Toutes ces modifications sont censées casser le programme. Nous voulons apporter des modifications qui cassent de manière fiable un programme. En supposant que nos tests soient bons, ils doivent détecter le problème.
Couverture de mutation
- Les résultats des mutants combinés eux-mêmes constituent une forme d'aperçu de la couverture :
- Mutations que nous avons pu identifier avec nos tests : Bien. Ligne verte dans notre code.
- Mutations que nous n'avons pas pu identifier avec nos tests : Mal. Ligne rouge dans notre code.
- Ainsi, nous pouvons utiliser le ratio de succès (fraction de toutes les mutations que nous avons identifiées) comme rapport de couverture de mutation.
- Donc, à la fin de la journée, nous avons deux couvertures :
- Couverture des tests traditionnels : Combien de lignes de code total sont couvertes par au moins un test.
- Couverture des tests de mutation : Combien de mutations de toutes peuvent être identifiées par au moins un test.
Une faible couverture traditionnelle entraîne une faible couverture des tests de mutation.
Une faible couverture traditionnelle gêne les tests de mutation. Les lignes qui ne sont pas couvertes dès le départ ne peuvent pas être couvertes par un test de mutation.
Pitest
Pitest, ou PIT, est un programme pour :
- Générer automatiquement des mutations
- Comparer automatiquement les résultats des tests
- Produire automatiquement un rapport de couverture de mutation.
Pourquoi celui-ci ?
- Pitest est très facile à intégrer, en tant que plugin IDE et maven.
- Pitest est extrêmement rapide :
- Ne mutile pas ce qui n'est pas couvert traditionnellement.
- Crée des mutants en modifiant directement le bytecode, pas besoin de compiler les mutants.
- Pitest propose une longue liste de mutateurs par défaut :
- CONDITIONALS_BOUNDARY
- EMPTY_RETURNS
- FALSE_RETURNS
- INCREMENTS
- INVERT_NEGS
- MATH
- NEGATE_CONDITIONALS
- NULL_RETURNS
- PRIMITIVE_RETURNS
- TRUE_RETURNS
- VOID_METHOD_CALLS
Intégration Maven
- Junit 5 vient avec son propre moteur de test, pour l'intégration avec PIT nous avons besoin d'une dépendance supplémentaire :
- Le fragment
pom.xmlci-dessous ajoute pitest en tant que plugin Maven :<!-- Both Surefire integration tests and PIT are bound to the verify phase. We want to run integration tests before PIT, because integration tests are faster, and we do not want to run PIT if there are integration failures. To overcome, we place PIT after surefire in the pom configuration file.--> <!-- HTML report available at: target/pit-reports/index.html --> <plugin> <groupId>org.pitest</groupId> <artifactId>pitest-maven</artifactId> <version>1.17.1</version> <configuration> <mutationThreshold>65</mutationThreshold> </configuration> <!-- Mutation tests are expensive (slow), and there's no point in executing them if common tests fail. Therefore we execute them later, in the verify phase.--> <executions> <execution> <id>mutation-tests</id> <goals> <goal>mutationCoverage</goal> </goals> <phase>verify</phase> </execution> </executions> </plugin> - Pitest est lié à la phase
verifydu cycle de vie par défaut :- Lancez avec :
mvn clean verify - Peut aussi être lancé individuellement (sans exécution du cycle de
vie) :
mvn org.pitest:pitest-maven:mutationCoverage
- Lancez avec :
Rapport Pitest
- Le rapport de couverture de mutation est disponible dans le répertoire
target:target/pit-reports/index.html- Peut être récupéré par le runner CI ;)
- Le rapport comprend deux sections :
- Répartition globale de la couverture :

- Couverture des tests traditionnels par package.
- Couverture des tests de mutation par package.
- Couverture des tests de mutation par classe et détails :
- Vert : tous les mutants ont été tués. Aucun signe de tests zombies.
- Rouge : au moins un mutant a survécu. Vous avez au moins un test zombie.
- Nombre sur le côté : Détails des mutants.
- Répartition globale de la couverture :
J'ai des zombies, que faire maintenant ?
- Révisez les zombies ! Revisitez vos tests et assurez-vous que les mutants survivants sont tués.
J'ai 100% de couverture de lignes, et 100% de mutations. Cela veut dire que je n'ai pas de bugs ?
Non, il est toujours impossible de prouver l'absence de bugs avec les tests. Néanmoins, vos tests sont robustes contre les mutants et vous avez testé tout votre code. Vous êtes raisonnablement à l'abri.
Tests d'intégration
Dans le premier cours sur les tests, nous avons déjà appris que les tests d'intégration ciblent "l'interaction de plusieurs modules".
Voyons maintenant comment nous pouvons utiliser la syntaxe JUnit pour les tests d'intégration :
- Tout d'abord, la terminologie est trompeuse : nous utilisons la syntaxe JUnit, mais pas pour les tests unitaires.
- L'idée principale est que nous allons utiliser la syntaxe d'annotations connue, mais en ciblant des tests non unitaires.
Configuration de Maven
Une première considération est que les tests unitaires et les tests d'intégration ne doivent pas se dérouler dans la même phase.
| Type de test | Phase Maven |
|---|---|
| Tests unitaires | test (Phase 3) |
| Tests d'intégration | verify (Phase 5) |
- Cela signifie que si nous utilisons la même syntaxe de test, nous devons trouver un moyen d'indiquer à Maven comment
certaines classes de test doivent être exécutées dans la phase
test, tandis que d'autres doivent être exécutées dans la phaseverify. - Une méthode simple consiste à utiliser un préfixe ou un suffixe pour identifier les tests d'intégration.
- Exemple :
- Les classes de test se terminant par
IT(suffixe) sont considérées comme des Tests d'Intégration et seront réservées pour la phaseverify, par exempleAutomatedGameSessionsIT.java. - Les classes de test se terminant par
Test(suffixe) sont considérées comme des tests unitaires classiques et seront exécutées dans la phasetest.
- Les classes de test se terminant par
Respectez les conventions
Les suffixes ci-dessus sont des conventions largement répandues. Le plugin Maven pour les tests unitaires (Surefire) recherchera et exécutera par défaut uniquement les classes de test dont le nom se termine par Test.
Configuration Maven pour les tests d'intégration
Les tests JUnit de base ne nécessitent pas de plugin Maven. Cependant, dès que nous voulons personnaliser l'exécution de nos classes de test, nous pouvons utiliser le plugin Surefire, qui permet des configurations de test plus avancées.
La configuration ci-dessous exclut toutes les classes de test se terminant par *IT.java de la phase
standard mvn test, puis définit une deuxième catégorie de tests (correspondant aux fichiers précédemment exclus) pour
la phase verify.
<!-- Plugin to associate files ending with IT to integration test phase (verify) and all other test to test phase (test)-->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>3.5.2</version>
<!-- exclude all files ending on *IT from the standard unit test phase -->
<configuration>
<excludes>
<exclude>**/*IT.java</exclude>
</excludes>
</configuration>
<!-- define an extra test run, containing exactly the files we previously excluded -->
<executions>
<execution>
<id>integration-test</id>
<goals>
<goal>test</goal>
</goals>
<!-- associate with the maven verify phase -->
<phase>integration-test</phase>
<configuration>
<excludes>
<exclude>none</exclude>
</excludes>
<includes>
<include>**/*IT.java</include>
</includes>
</configuration>
</execution>
</executions>
</plugin>
Réference pour cette configuration: StackOverflow
Tests d'intégration pour les architectures Blackboard
Configurer le moment où une classe de test est invoquée ne suffit pas. Nous devons encore coder de vrais tests d'intégration !
Dans ce cours, vous avez travaillé avec des architectures de type blackboard. Dans le contexte MVC, cela signifie :
- La vue ne peut pas simplement demander au contrôleur d'effectuer un mouvement arbitraire.
- Au lieu de cela, le contrôleur fournit d'abord une liste d'options (expert sur le blackboard), puis la vue interagit avec le joueur humain pour déterminer quelle option est sélectionnée - et ensuite exécutée par le contrôleur.
On peut imaginer cette interaction comme un match de tennis :
- Le contrôleur fournit des options (en passant la balle).
- La vue, en interagissant avec un humain, retourne un choix (en renvoyant la balle).
Ce qui ralentit notre match, c'est l'interaction humaine. Cependant, si nous trouvions un moyen de supprimer cette interaction, nous aurions instantanément un test d'intégration (couvrant l'interaction de plusieurs composants du système).
Tests d'intégration pour Blackboard
Dans le contexte du blackboard, tout algorithme de prise de décision peut être transformé en test d'intégration. Pour les jeux, plusieurs stratégies peuvent être combinées pour créer des scénarios de test plus complets.
Nous allons maintenant examiner deux stratégies (primitives) de prise de décision :
Keksli
Keksli est charmant, mais profondément opportuniste. Lorsqu'il se voit offrir plusieurs options (par exemple, plusieurs serviteurs humains lui proposant de la nourriture), il choisira simplement la plus proche.

Comment pouvons-nous traduire Keksli en algorithme de prise de décision ?
Lorsque le contrôleur propose plusieurs options, nous choisissons instantanément la première et la transmettons au contrôleur pour exécution. Nous pouvons remplacer toutes les décisions des joueurs humains par des instances de Keksli et tester notre jeu. Cependant, la session ne représentera pas une partie jouée intelligemment.
Le déterminisme est essentiel !
Choisir "la première" option peut être non déterministe. Par exemple, si les options du blackboard fournies par le contrôleur sont dans un ordre aléatoire, les choix de Keksli ne seront pas déterministes, et donc, le test d'intégration ne le sera pas non plus. Toujours trier les options du blackboard avant de sélectionner le premier élément.
Mad Max
Mad Max est l'antagoniste féroce de Keksli. Mad Max n'a aucun plan et sélectionne simplement une action au hasard parmi les options proposées.

Comment pouvons-nous traduire Mad Max en algorithme de prise de décision ?
Similaire à Keksli, mais au lieu de sélectionner la première option, nous utilisons un PRNG (Pseudo Random Number
Generator) pour sélectionner
une option valide au hasard à chaque itération. Nous utilisons une combinaison de Math.abs et de Modulo pour
garantir que le nombre aléatoire est dans la plage correcte.
Si Mad Max choisit au hasard, devons-nous toujours trier nos options ?
Oui ! Nous voulons que notre prise de décision Mad Max soit indépendante de l'implémentation du contrôleur, c'est-à-dire qu'elle doit être déterministe et mener au même résultat, peu importe l'ordre initial des options sur le blackboard. Mad Max n'est pas véritablement aléatoire, son implémentation utilise un PRNG. Un tri initial est un moyen fiable d'obtenir des tests d'intégration déterministes !
Mocking
Souvent, arriver au point où vous pouvez commencer à tester n'est pas trivial. C'est particulièrement vrai lorsqu'on travaille avec des ressources internes et externes :
- Une base de données => Vous ne pouvez tester que si la BD est en ligne.
- Le système de fichiers => Vous ne pouvez tester que si certains fichiers sont présents sur le disque.
- Un service en ligne => Vous ne pouvez tester que si un certain service est accessible.
- ...
---
title: SUT needs a DataBase object
---
classDiagram
SUT *--> Database: has a
class Database {
<<Class>>
+writeToDB() void
+readFromDB() String
}
class SUT {
<<Class>>
+SUT_Constructor(DataBase) SUT
+doSomethingThatNeedsRepositoryRead() String
+doSomethingThatNeedsRepositoryWrite() void
}Interprétation : Le SUT nécessite un accès à une base de données. Nous ne pouvons pas tester le SUT sans une connexion BD entièrement fonctionnelle.
Les mocks remplacent les dépendances réelles du SUT
Lorsque votre SUT dépend de composants complexes, il est courant de remplacer ces dépendances par un substitut. Ces classes "Mock" imitent le comportement de la dépendance d'origine mais sont plus faciles à contrôler et facilitent grandement les tests.
Mocking à l'ancienne
En principe, aucun outil supplémentaire n'est nécessaire pour le mock testing. Une simple interface avec une implémentation en production et une implémentation Mock suffit :
---
title: SUT needs any Database implementation
---
classDiagram
Database <|-- ActualDatabase: implements
Database <|-- MockDatabase: implements
SUT *--> Database: has a
class Database {
<<interface>>
+writeToDB() void
+readFromDB() String
}
class ActualDatabase {
<<Class>>
+writeToDB() void
+readFromDB() String
}
class MockDatabase {
<<Class>>
+writeToDB() void
+readFromDB() String
}
class SUT {
<<Class>>
+SUT_Constructor(Repository) SUT
+doSomethingThatNeedsRepositoryRead() String
+doSomethingThatNeedsRepositoryWrite() void
}Interprétation : Le SUT possède deux méthodes que nous voulons tester :
doSomething...(). Ces méthodes appellent toutes deux le Repository en interne. Cependant,Repositoryest une interface, et nous pouvons passer une classe Mock au constructeur du SUT lors des tests.
Mockito
Essentiellement, tous les frameworks de Mocking reposent sur le même principe : remplacer des dépendances complexes par des implémentations Mock afin de faciliter les tests.
Cependant, il existe de bonnes raisons de préférer un framework de Mocking à une implémentation manuelle :
- Convertir des classes existantes en interfaces et configurer des classes Mock dédiées est une tâche répétitive et chronophage.
- Dans certains cas, il n'est pas possible ou trivial d'introduire des interfaces pour les dépendances des tests, par exemple si vous n'avez pas un contrôle total sur le code source.
Les frameworks de Mocking sont une question de commodité
Techniquement, vous n'avez pas besoin de frameworks de Mocking. Toutes leurs fonctionnalités peuvent être reproduites avec du code manuel. Cependant, ils sont conçus pour rendre les tests Mock aussi simples et minimalistes que possible. Avec les frameworks de Mocking modernes, vous pouvez remplacer des dépendances complexes avec un minimum de configuration.
Dans la section suivante, nous allons examiner de plus près la syntaxe du framework de Mocking Mockito.
Configuration Maven
Avant de pouvoir utiliser de nouvelles fonctionnalités facilitant le Mocking, nous devons informer notre système de build de la dépendance Mockito :
<!-- Mockito dependency, to gain access to additional annotations and testing mechanisms-->
<dependency>
<groupId>org.mockito</groupId>
<artifactId>mockito-core</artifactId>
<version>5.16.1</version>
<scope>test</scope>
</dependency>
Création d'un Mock
Nous allons reprendre l'exemple d'introduction, mais en le rendant un peu plus concret. Imaginons que nous ayons une
classe StudentPrinter (SUT), et que pour des tâches visuelles de base (par exemple, l'affichage de la liste des
étudiants), StudentPrinter ait besoin d'un accès à une StudentDatabase.
---
title: SUT needs a DataBase object
---
classDiagram
StudentPrinter *--> StudentDatabase: has a
class StudentDatabase {
<<Class>>
+writeToDB() void
+readFromDB() String
}
class StudentPrinter {
<<Class>>
+StudentPrinter(StudentDatabase) StudentPrinter
+getAllStudentsFormatted() String
+getAllStudentsWithPrefixFormatted(Char) String
}Rappel : Nous ne sommes pas intéressés par les tests de la classe
StudentDatabase, nous voulons uniquement tester les méthodes deStudentPrinter. C'est pourquoi il est légitime de remplacer la classeStudentDatabasepar un mock lors du test deStudentPrinter.
Dans notre classe de test du SUT, nous n'avons plus besoin d'instancier un objet StudentDatabase. Nous utilisons
plutôt une annotation pour informer Mockito que nous avons besoin d'une classe mock.
- Ancien code :
- Nouveau code:
Les annotations ne sont pas automatiquement scannées
Les extensions Mockito sont une extension de la syntaxe Java standard et utilisent la réflexion (un concept avancé de Java). Sans entrer dans les détails, pour que toutes les annotations Mockito fonctionnent, nous devons d'abord activer le scan des annotations. Cela se fait généralement dans la méthode @Before : MockitoAnnotations.openMocks(this);
Utilisation d'un Mock
Jusqu'à présent, nous avons seulement créé le Mock. Cependant, notre SUT n'est pas encore créé.
Nous avons deux options :
- Sans annotation, créer manuellement le SUT dans la méthode
@Before: - Avec annotation, laisser Mockito créer le SUT :
Qu'est-ce qu'un Mock, déjà ?
Un Mock est une classe qui prétend être autre chose. Elle offre les mêmes méthodes, avec les mêmes signatures. Cependant, par défaut, elle ne fait absolument rien. Toutes les valeurs retournées sont null et aucune fonctionnalité interne n'est jamais déclenchée par un appel de fonction.
Tester avec un Mock
Puisque le Mock remplace l'implémentation originale, nous n'avons plus besoin d'une connexion à une base de données réelle, de la réponse d'un serveur, de l'état du système de fichiers, etc...
Les Mocks nécessitent tout de même une configuration !
Tous les appels à un Mock retournent par défaut null. Cela signifie que nous ne pouvons pas tester quelque chose de significatif immédiatement ! Utiliser le résultat de n'importe quel appel à un Mock entraînera une NullPointerException.
- Cependant, les Mocks peuvent être "informés" pour retourner des valeurs spécifiques pour des entrées spécifiques.
- Pour ce faire, nous utiliserons la syntaxe
when-thenReturn. - Exemple :
// When someone asks the mock to get all students, return an Array with three mock names. when(studentDatabase.getAllStudents()).thenReturn(new String[] {"Roman", "Maram", "Quentin"}); // When someone asks the mock to get all students starting with an `M`, return another Array with mock names. when(studentDatabase.getAllStudentsStartingWith('M')).thenReturn( new String[] {"Max", "Maram", "Mohamed"});
Quel est le résultat du mock pour studentDatabase.getAllStudentsStartingWith(X) ?
La syntaxe when-thenReturn est spécifique à l'entrée. Nous n'avons pas configuré ce qui doit être retourné pour l'entrée X, par conséquent, l'objet Mock retournera null.
Captors
Parfois, nous ne sommes pas intéressés par ce qui est renvoyé par un Mock, mais par ce que le SUT passe à un Mock.
- Mockito offre une annotation spéciale pour "capturer" les paramètres au fur et à mesure qu'ils sont envoyés à un Mock.
- Nous pouvons également
verify(vérifier) que le Captor a été déclenché, c'est-à-dire que le Mock a bien été appelé. - De plus, nous pouvons inspecter et affirmer les valeurs concrètes des paramètres avec les déclarations
assertstandard de JUnit.
Exemple :
// Define a Captor:
@Captor
private ArgumentCaptor<Character> characterCaptor; // Captures String arguments
//... Later, an actual junit tests that uses the captor:
@Test
public void spyOnCallParametersTest() {
// Finally we can spy on the previous method calls, to verify if parameters have been
// correctly passed to the object we spy on (by the SUT)
studentPrinter.getAllStudentsWithPrefixFormatted('A');
verify(studentDatabase).getAllStudentsStartingWith(characterCaptor.capture());
assertEquals(Character.valueOf('A'), characterCaptor.getValue());
}
Spies
Enfin, il y a la situation où vous voulez utiliser la puissance de Mockito, mais sur des objets réels, et non des Mocks.
Qu'est-ce que cela signifie ?
- Nous ne remplaçons pas une dépendance (par exemple, une base de données) par un Mock.
- Cependant, nous surchargeons le comportement pour des entrées spécifiques sur des appels de méthode spécifiques, en
utilisant la syntaxe
when-thenReturn. - De plus, nous pourrions vouloir inspecter les paramètres passés au mock, en utilisant les
Captors.
La seule différence réside dans l'annotation que nous utilisons pour notre dépendance. Puisque nous utilisons la
dépendance originale, mais que nous espionnons son comportement, nous utilisons l'annotation @Spy.
Exemple :
/* In this more advanced example we use the Spy annotation. That is we use the original
* dependency, but spy on its behaviour using verify, and only override very specific usage
* scenarios with the `when`-`thenReturn` syntax.
*/
@Spy
private StudentDatabase studentDatabase = new StudentDatabase();
Littérature
Inspiration et lectures supplémentaires pour les esprits curieux :
- Piotr Kubowicz: Mutation Testing - Too good to be true ?
- Tomek Dubikowski: Zombies VS Mutants
- PIT (pitest): Mutation testing basics
- Vogella: Mockito Tutorial
- Martin Fowler: Modern Mocking Tools
- Baeldung: Mockito Article Series