Continuous Integration
In this unit we discuss the underlying concepts of server sided continuous integration practices on the example of GitLab. You will be learning how to create a reliable container environment for maven projects and how to integrate automatic quality checks on every pushed commit.
Lecture upshot
Gitlab runners allow your to systematically run the entire maven build lifecycle on every code modification. Direct feedback on the quality checks perdformed on every commit are an essential concept for ensuring a reliable and stable codebase.
CI definition and motivation
- Continuous Integration (or short "CI") aims at supporting project success by having developers regularly send their code to a central repository and performing automated builds and tests.
- In previous lectures you've already seen two building blocks to support these goals:
- Build systems, e.g. maven: Highly configurable, use textual representation for explicit definition of build process and code quality requirements.
- Version control systems, e.g. git: Synchronization of work effectuated by developers, using separate machines.
A need for CI configurations
- Both components provide an essential functional component for CI, but:
- There is no guarantee developers use the build system reliably before pushing code
- There is no direct visual feedback on build system feedback, when combining work
- CI is most relevant when combining work, i.e. when pushing commits or merging branches. In essence, you want to...
- enforce that developers use branches for features, and cannot directly work on
main. - be sure the work about to be merged into
mainis not breaking anything previously working.
- enforce that developers use branches for features, and cannot directly work on
- Without a CI configuration, you have no guarantee about the state of your
mainbranch, in the worst case:- Your TP submission misses points, because you did not submit something well tested and working.
- You present recent progress to a client, but the demoed version actually has fewer working features because the last fast push broke everything.
- You send out a security patch, and now millions of PCs are caught in an infinite boot loop.
CI configurations are a safety mechanism
A good CI configuration ensures one thing: A protected main branch that cannot be corrupted, neither by honest mistake nor by blatant recknessness. Whatever happens, your project goes only forward, never backward.
In the remainder of this lecture we'll take a look at how to set up various protection mechanisms using GitLab.
Server sided checks example
- Trust is good, control is better: The only way to reliably know whether a commit is "good", is to assess it on server side.
- What checks should be run on server-side to assess "good" ?
- Does the software actually compile?
- Is it documented?
- Does it respect checkstyle?
- Is it tested, is the coverage high enough?
- Is there clutter in the repo, e.g.
classfiles? - ...
-
As we'll see shortly, exactly this is possible with GitLab:
- Once configured correctly, GitLab will provide you with fine-grained information on various quality checks for each commit:
- Based on the test results, we directly get a sense for a commit's quality:
- All checks Passed
- Some checks with Warning
- At least on checks Failed
- Illustration:

Note: With "checks", we're not only referring to unit tests, but all thinkable code quality checks (including unit tests).
Merge, don't push
- A key protection for any repository is to prohibit direct pushes to
main.- See:
Settings -> Repository -> Branches -> Protected branches
- See:
- Whatever feature added, must be first pushed to a branch.
- If some attempts to directly push to main:
- Instead of merging code locally and then pushing, you'll merge on server side, using merge-requests.
Merge requests
- Merge requests translate to:
"I've created something useful on abranch, please add it tomain".- Often times the person actually merging is not the developer.
- To initiate the process, the developer creates a new merge request. (GitLab webui, big banner)
- Ideally, the merge request itself offers all information of server-sided checks at a glance
The actual CI merit
It does not matter if the code works on the developer's machine, it only matters if the code works for the client. Server-side checks give piece of mind to whoever has to decide on a merge request.

Containers as CI background
- The idea of server-sided checks is charming.
- But testing the software also means the server must be able to compile and run the software.
- Reminder: Dynamic testing requires code execution.
- We cannot run server side tests, unless the server has:
- The source code
- An operating system, allowing us to run code
- All program related SDK requirements: Maven, Java compiler, JVM
- Gitlab naturally has the source code, but absolutely not the environment.
How to provide an environment
- The classic approach of installing a software development environment is not viable.
- You cannot walk to the server running GitLab and yourself start to install Maven, Java compiler, JVM
- Time-consuming
- Requires root access
- Not reliably replicable
- In the classic, native approach you have a stack of three components:
- Software
- Libraries needed for software
- Operating system providing kernel to run libraries and software.
- There are two ways of interfering with this stack to obtain software, without installing requirements manually. Both modify the above native stack:
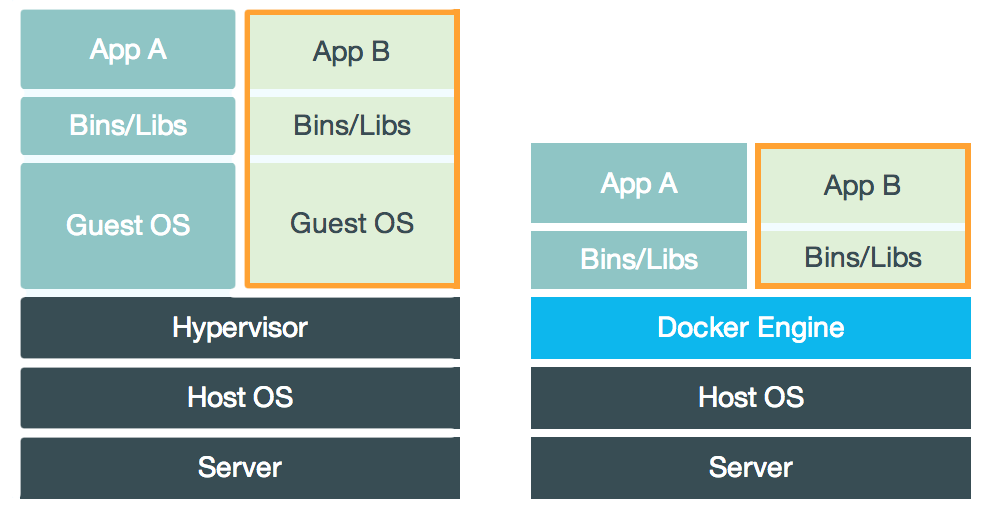
Virtual machines
- Virtual machines are a snapshot of an entire operating system, i.e.
- An OS kernel (e.g. windows)
- All libraries
- The actual software
- Shipping a virtual machine is reliable, however:
- Performance drop: An intermediate Hypervisor is needed to simulate an entire OS top of an existing OS kernel.
- Voluminous: An entire OS is shipped along with the few software components actually needed.
The JVM is not that kind of VM.
The JVM is not to be confused with operating system VMs. The JVM only interprets java bytecode. Operating system VMs can run any bytecode, that is, run any software the simulated machine could run (such as e.g. a JVM).
Docker containers
- Docker containers are a response to operating system virtual machines.
- Docker containers only provide the required libraries and software, and reuse the existing host OS kernel.
- Usually not even the container itself is shipped, only instructions on how to create it step by step (also called Images).
- Compared to VMs, docker images are:
- Small in size.
- Compared to VMs, docker containers are:
- Almost as performant as the host system (e.g. the GitLab server on which they run).
GitLab context
- Docker images are like blueprints, telling a machine what exactly is needed to work with a project.
- A server, e.g. GitLab, can use such an image to construct a reliable environment, e.g. to obtain a java compiler, JVM,
maven, etc...
- Pointing to the right image is a single line of code
- Once the image provided, there is no need to manually install java compiler, JVM, maven, etc...
Why is this useful for GitLab ?
- We can tell GitLab to use an image leading to a reliable environment.
- Using that environment we can assess our source code on server side.
- We can assess excessively, and fast.
Gitlab CI
Almost all configuration GitLab CI configutation is done with just a single file: gitlab-ci.yml
- It only needs to exist, that is as soon as it is in your project repo and pushed, GitHub will use it.
- Whatever we specify in this file, GitLab will try to assess source code on every commit, based on the contained instructions.
The first thing we add to the file, is the reference to the docker image to use.
- In the context of INF2050, we'll always use the line:
image: maven:4.0.0-rc-4-amazoncorretto-24 - This image leads to a container environment with:
- Java 21 (JVM + Compiler)
- Maven
- Since the container runs on a linux server, we also get access to all standard linux commands !
YAML syntax
- Next we'll take a deeper dive into the exact way of defining the CI process for GitLab, using the
file:
gitlab-ci.yml - For things to be understood by GitLab, we have to stick to
the exact requested keywords.
- The file ending is
yml, which stands forYAML, the acronym for Yet Another Markup L anguage. - YAML files, similar to
XMLfiles, orJSONfiles must respect the correct formatting and keywords.
- The file ending is
- We've already seen how to specify the CI image to use.
- Next we'll look into how to specify the main components of a CI configuration, using GitLabs formatting and
keywords.
In details we'll look at:- How to define custom stages (the order of things to happen)
- How to define what jobs (the exact individual things to happen)
What's the relationship between YAML and GitLab ?
GitLab uses the YAML notation for configuring the CI behaviour. There are many other YAML files, using the same syntax, but not necessarily the same keywords.
General YAML notation
All yaml files are dictionaries and use a key/value notation.
- (Optional) document start marker:
--- - (Optional) document end marker:
... - Dictionary key:
foo: - List of item values:
-- Abbreviated form, only values:
['value1', 'value2', '...'] - Abbreviated form, dictionaries:
{ name: Max, job: Professor, age: 35 }
- Abbreviated form, only values:
Example:
---
# After file start marker, enumerate all key/value pairs.
university: UQAM
course: INF2050
students: 164
# Next an entry with multiple values for same key
staff:
- Max
- Fatoumata
- Paul
- El Mehdi
- Leila
prerequisites: [ 'INF1070', 'INF1120' ]
...
YAML is a JSON superset
YAML is a JSON superset with emphasis on human readability. Every JSON file is also a valid YAML file, but not the other way round.
Defining stages
Similar to maven, GitLab's CI configuration foresees a certain order of things, common to most software projects:
- preparation
- building the software
- testing
- deploying
- post completion
These are called stages:
-
Whenever we define a new job, we need to explicitly state at which phase it should take place.
- For this we use the below keywords:
-
If we want to add additional stages, we can do so by listing them in the
.gitlab-ci.yml:- Note however, that all default stages are overruled as soon as we define our own set.
-
The individual jobs (which we'll define next) will each belong to exactly one phase.
- Since the phases define an order, we also refer to the CI execution as a "CI pipeline".

Defining jobs
- A job definition is in essence one or multiple commands to execute.
- We can use any of the commands provided by the container
- Since the container is built on an image for java / maven, we have the
java,javac, andmvncommand. - On top, we can use any standard linux command.
- In YAML syntax, we have to describe
- The job name.
- The stage at which to execute the job stage.
- The commands to be called by the job
- Example:
Runner stage behaviour
The definition of stages seems somewhat contrived, why would we ever need to define stages, and not just define all jobs in a sequence ?
- There's a natural interest in the CI execution not taking overly long.
- If all jobs are performed sequential, we're potentially not making best use of the server resources.
- But not all jobs should be run in parallel.
Examples:- Testing for Checkstyle and Javadoc in parallel is ok. There is no dependency.
- Building a JAR file in parallel to compiling files is not ok. There is a dependency,
Stages allow improved resource consumption:
- All jobs within the same stage are executed in parallel.
- All jobs of subsequent stages are executed sequentially. Later jobs are cancelled if at least one job of an earlier stage failed.
Visualization of three phases, with parallel and sequential jobs:

Source: doc.gitlab.com.
Maven CI configuration
The previous example was pretty pointless:
- We do not just want to call linux commands...
- We want to call commands that assess our source code!
Simplest case
In the simplest case, we use some of the standard linux commands to verify if the repository is free of compiled code:
check-clutter-job:
stage: lint
script:
- CLUTTER=$(find . -name \*.class)
- if [[ ! -z $CLUTTER ]]; then exit 1; else exit 0; fi
Explanation:
- The first script line stores a list of all class files in a variable
- The second script checks if the variable is empty:
- Variable not empty returns
1(job failure) - Variable empty returns
0(job success)
- Variable not empty returns
Atomic maven build
Still, we're not yet making use of the container!
- We've selected the image, specifically because the resulting container allows us to use maven
- We already have a
pom.xmlconfiguration in our project, with many quality checks, let's use it!
- In this case the CI pipeline is atomic. It has just a single pipeline job, doing all the heavy lifting.
Can you use the above image for a python project
No. The image has to match the project requirements and a java/maven image cannot be used to create a container for python processing. A Runner cannot possibly work if not all requirements are satisfied by the container.
Maven phases as stages
-
Using a pipeline with just a single command works as code quality check.
- However, if our build fails, we do not immediately see what is the issue.
- Notably for merge requests, this is inconvenient.
- It would be a lot better to have individual pipeline stages, for the individual maven phases.
-
The fist step would be to define all maven phases as stages:
- Afterward, we can define individual maven jobs for each pipeline step:
validate-job:
stage: validate
script: "mvn clean validate -B"
compile-job:
stage: compile
script: "mvn clean compile -B"
test-job:
stage: test
script: "mvn clean test -B"
package-job:
stage: package
script: "mvn clean package -B"
Lifecycle redundancy
- By default, maven will execute the entire lifecycle until the specified phase, for every individual
mvncommand in a runner.- That is quite wasteful, e.g. we only need to lint once, to ensure the code is correctly formatted.
- Better would be to run the phases individually.
- Unfortunately maven does not quite allow single-phase execution.
- But there's a trick: We can carry forward build artifacts, and run individual plugins (not phases) on them.
- We'll practice this technique for resource optimization in the next lab session.
Runners are isolated
Careful though when building a sequential pipeline for individual maven phases. The artifacts added to target are not automatically carried forward from one runner to the other. For subsequent runners to work, we have to manually define which artifacts, from which previous runner to reuse.
Using build artifacts
Each runner lives in its own environment, which you can think of as a sandbox.
- Whatever files produced by one runner are not immediately visible to another runner. It is as if they were operating on two separate machines.
- But sometimes you want to preserve something generated by a runner, to retain information on a commit.
- Examples:
- The
surfireplugin produces a test report totarget - The
jacocoplugin produces a coverage report totarget - The
javadocplugin produces a navigable website source code totarget
- The
- All these generated files are lost, as soon as the creating runner goes back to sleep.
Luckily there's a configuration keyword to instruct GitLab to extract files from a runner, before its dissolved:
job-name:
script:
# Run some command that produces files, e.g. maven calling javadoc plugin.
- command-that-produces-files
# Define which files / folders created by this runner should survive the build process.
artifacts:
paths:
- folder-to-survive-runner
Next we'll take a look at how artefacts form various build stages are best used for additional feedback on your commit quality.
Test example
- Usually it does not suffice to know that some test failed, you want to know exactly which tests failed.
-
Gitlab provides a dedicated interface to display this information, however you have to provide it.
- This is done by means of a build artifact!
- You can simply extract the test report created by maven (in your
targetdirectory), and GitLab will automatically add a new tab to each commit with the detailed test report:
-
If you also have a coverage plugin configured, e.g.
jacoco, you can likewise extract coverage reports for additional insight.
test-job:
stage: test
script: "mvn clean test -B"
artifacts:
when: always
reports:
junit:
- target/surefire-reports/TEST-*.xml
- target/failsafe-reports/TEST-*.xml
coverage_report:
coverage_format: jacoco
path: target/site/jacoco/jacoco.xml
JavaDoc example
A second artifact type that you should extract is generated documentation.
- The JavaDoc plugin already creates decent, human-readable documentation in the target folder.
- Likewise, GitLab has a built-in feature to repository files on a webserver, for convenient browser access.
- However, unless you are an oldschool webpage coder, your website is most likely generated, not hand-written:
- HTML files.
- CSS files.
- JavaScript files.
- But wait! We do not want any generated files in our repository!!
- Let's use a CI pipeline job to generate the documentation on server-side, save the artifact, and only then host the documentation on the internet!
- The first thing we need to do is configure the CI job to move whatever documentation created into a folder
named
public.
pages:
script:
- mvn javadoc:aggregate
- mkdir public
- cp -r target/site/docs/apidocs/* public
# Define which files / folders created by this runner should survive the build process.
artifacts:
paths:
- public
-
Once the runner configured, you still need to tell GitLab to actually host the javadoc on its file-server:
-
Access your GitLab project on the GitLab webui
- On the left side-bar, select
Deploy -> Pages - Optional: Deselect the custom URL checkbox
- Access your project's webpage.
Only on main
- A caveat with documentation, is that it is only relevant for released software, i.e. no one cares about documentation for some feature still in the making on some secret branch.
- That translates to: we only want to deploy documentation for commits on the
mainbranch. - Luckily there is an extra keyword for restricting runners to specific branches:
pages:
script:
- ...
# Only keyword allows restricting for which git branch the job is applied.
only:
- main
MISC
This course content is provided to you, with the help of a GitLab CI pipeline !
- I write sources in MarkDown format
- I push the sources to a GitLab repo
- GitLab runs a CI pipeline that:
- Creates a container with python support
- Uses a python program to translate:
- Markdowns into navigable and indexed HTML pages
- Mermaids into SVGs
- HTML and SVGs into a PDF
- Stores the produced HTML/SVG/PDF artifact in the public folder
- GitLab serves the course websites on its file server, at https://inf2050.uqam.ca/en/
Every time I change a singe typo, the entire CI pipeline is re-executed, and the webpages automatically update on every push. :)
Literature
Inspiration and further reads for the curious minds: